
If you arrived here first, we’d recommend you read Part 1 of this blog series before continuing for better context —
Part One — The Evolution of Work : The Case for Scaling Business Operations using Humans and AI.
If you’ve already finished reading it, here’s your cookie.

Deploying HI (Human Intelligence) and AI (Artificial Intelligence) requires you to rethink your entire business process. Go back to the drawing board and break the entire process down to create an efficient supply chain.
Account for both efficiency (making the best use of resources) and effectiveness (achieving the desired outcome). Here are all the steps for that presentation you make for your boss which will get you that long awaited promotion:
- Define the Outcomes of your Process (why all this trouble?)
- Define the Broad Workflow (big picture stuff)
- Define your Rule Engine and Operational Guidelines (IFTTT)
- Design your First Workflow (whiteboard)
- Optimize your Workflow (look at historical data)
- Think Worker Training (nobody likes this but it’s there)
- Think Quality Control (what will make everyone more miserable?)
- Think Automation (yay!)
- Rinse and Repeat (Until you can successfully retire on that island)
These are a lot of big steps. The idea is to give you a quick flavor for each one and share our learnings. This is a lot of work (it took us a while to write this blog too). We intend on covering each step in much greater detail in subsequent blog posts as well.
A Simple Example
To work through all the steps, we decided to follow a simpler example. Because we all love shopping online, let’s take a look at marketplaces like Amazon or Alibaba.
Every day, product marketplaces onboard millions of new SKUs in aggregate. For perspective, Amazon adds close to half a million products on average every single day (and this is old data!). Each listing has several (sometimes dozens of checks). Marketplaces must curate and quality control each of these listings, check images, descriptions, pick out the right category, highlight the correct attributes, have the right meta-tags, find the right recommendations, etc — it’s fairly elaborate! This problem applies to most marketplaces, real estate platforms, and social media companies. Basically, anyone generating a lot of user generated and 3rd party content.
STEP 1
Define the Outcomes of your Process (why all this trouble?)
To prepare for that level of scale, the process has to be:
- Fast — the faster a product goes live, the faster it sells.
- Cost Efficient — obviously!
- Flexible — Q4 in the US sees a massive spike in volumes and the system needs to keep up with higher volumes, and
- Quality Controlled — because the stakes are high! Consider the user experience impact and potential bad press from counterfeit products, offensive content, racist comments, etc.

Things you want…
STEP 2
Define the Broad Workflow (big picture stuff)
While there can be a whole lot of things that Amazon would do, to keep things simple, let’s say the process has 2 parts to it:
- Quality Control of Product Listings: Quality control is driven by Acceptable Use Policies (AUPs) to ensure listings are as per platform guidelines, moderates prohibited listings and NSFW. This drives better platform user experience through consistency and quality. It also ensures that content is Brand Safe. You don’t want dick pics or fake $20 Gucci bags on your site.
- Enrichment of Product Listings that are Quality Approved: Enrichment is driven by adding more attributes and tags to products. This helps drive better site navigation through filters and discoverability and lets your users find what they’re looking for. If they can’t find it, you can’t sell it.
These interventions, amongst other things, help offer richer user experience to increase conversions, increase order value, promote discovery and cross-selling, reduce site abandonment, and improve brand credibility.

More things that you want
Here’s what the workflow looks like –
You first run Quality Control. Everything that gets approved gets enriched. This one’s a no-brainer — you only enrich quality approved listings
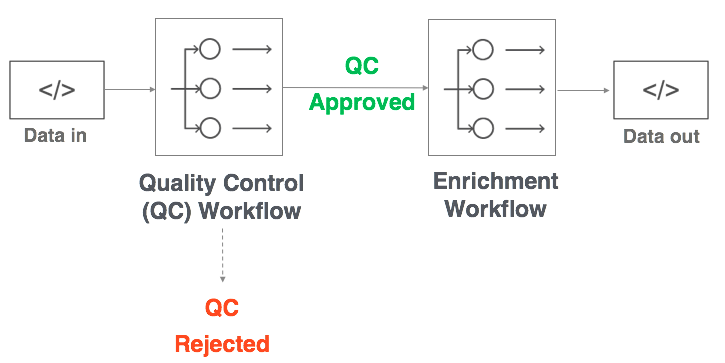
Workflow for your data Quality Control and Enrichment
STEP 3
Define your Rule Engine and Operational Guidelines (IFTTT)
We cannot stress enough on how important this is. Lack of clarity here is like hiring a candidate without the job description! Until such a time you have it narrowed down, to the teeth, we’d recommend keeping it simple and aligned with basic business objectives.
You’d be surprised to know that there are unicorns today that don’t have a clue about the guidelines or the taxonomy they want to use. Some of them have grown so quickly, there’s sometimes very little thought that goes into what’s ok and what isn’t.
Especially in e-commerce, a simple way to do this is to see what Amazon’s doing 🙂 However, what might work for them might not work for you so it’s definitely worth spending more time to think about it.
Here’s a simple set of guidelines for quality control for images

This is merely scratching the surface. There are lots of ways to get standard guidelines for the industry you’re in. We will do a detailed post on this soon!
STEP 4
Design your first workflow (whiteboard)
This is just a more elaborate version of the workflow in Step 2.
- Your data flows in.
- Humans check the quality of the listing based on rules in Step 3.
- Approved listings move forward. Rejected listings stop here.
- Approved listings are categorized because commerce has SO MANY categories, and each category has a different set of features or attributes. You separate the shirts from the mobile phones here. The reason to do this is efficient supply chains.
- Depending on the category selected, humans add attributes for each category, separately. If you only sell mobiles and shirts, you’re better off having fashion experts and electronics experts to do different things. Good luck getting fashion experts though
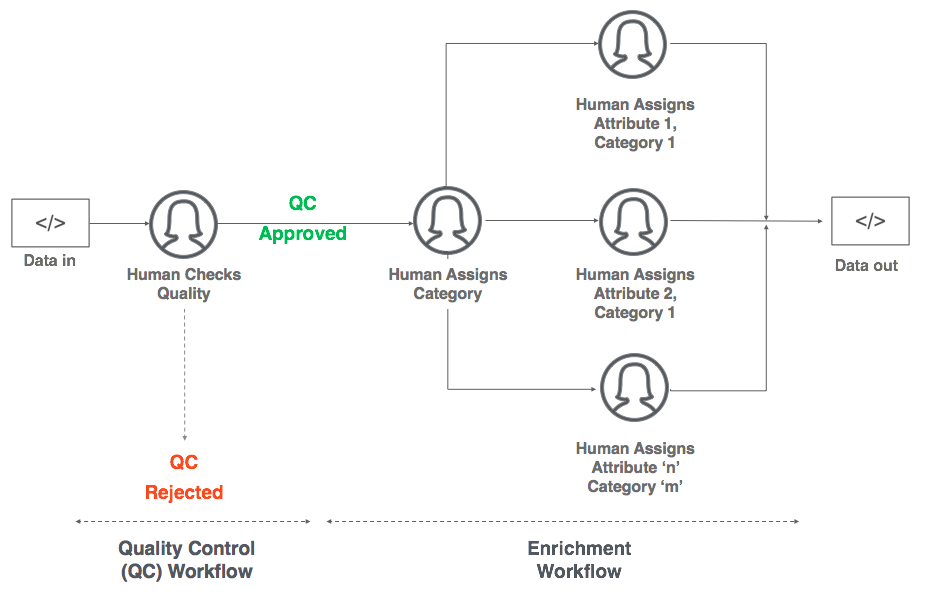
Detailed workflow for data Quality Control and Enrichment
Compared to one person doing all the work (meaning doing a bunch of different, but related tasks, and constantly context switching), supply chains, if done correctly, can create efficiency. An individual focused on the same type of task can be skilled to excel at that one task with fewer distractions, can work on a larger data set at the same time, and work on additional optimizations (More on optimization later).
For tasks that require someone to view all task outputs and take a call, we recommend doing those after all the base level checks have been made.
STEP 5
Optimize your workflow (look at historical data)
The devil is (always) in the details. There are a whole bunch of ways to analyze your historical data but this is not about analytics. We’ve mentioned a few examples that hold true.
- How your guidelines and taxonomy have evolved over time and how has it affected your sellers?
- Are your top sellers adhering to these guidelines?
- Are you keeping listings you do not want on your site away, etc.

An iPhone case shaped like a gun made its way to Amazon but was later pulled down
80/20 rules
Without going into all other details, let’s look at one scenario. Most datasets follow a Pareto principle like the 80/20, 70/30, or some such rule. For the uninitiated, this means that 20% of something is responsible for 80% of some related thing. It’s worth checking your data set for this anomaly. Assuming this holds true, it opens up an opportunity to optimize the workflow.
We’ll get to that in a minute…

65/35 rule in the sample dataset
Assuming the 80/20 (or similar rules) holds true
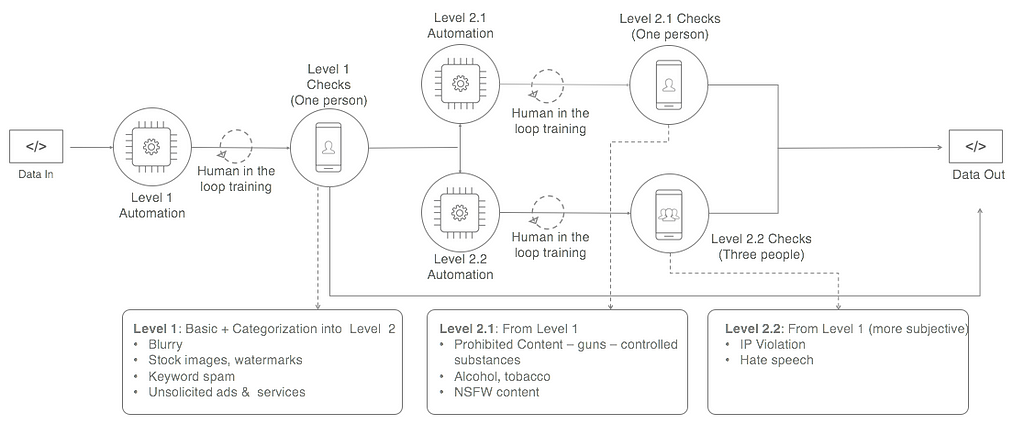
Let’s assume the 65/35 rule applies here. To build in optimization, you can break the task down into 2 steps. In this particular case, it resulted in 40% cost reduction. Workflow like a boss.
- In Step 1, check for the primary issues (the 65% issues are covered by 35% of your guidelines. If these get resolved here, you can end the sequence. If they don’t, you can move to step two.
- In Step 2, you can run the next two checks in parallel. You can do them serially if your data tells you to. In this specific case, we got 3 people to do check 2.2 instead of 1 person, which is usually the case. This is to account for quality and subjectivity for those specific guidelines of IP Violation and Hate Speech. More on that later.
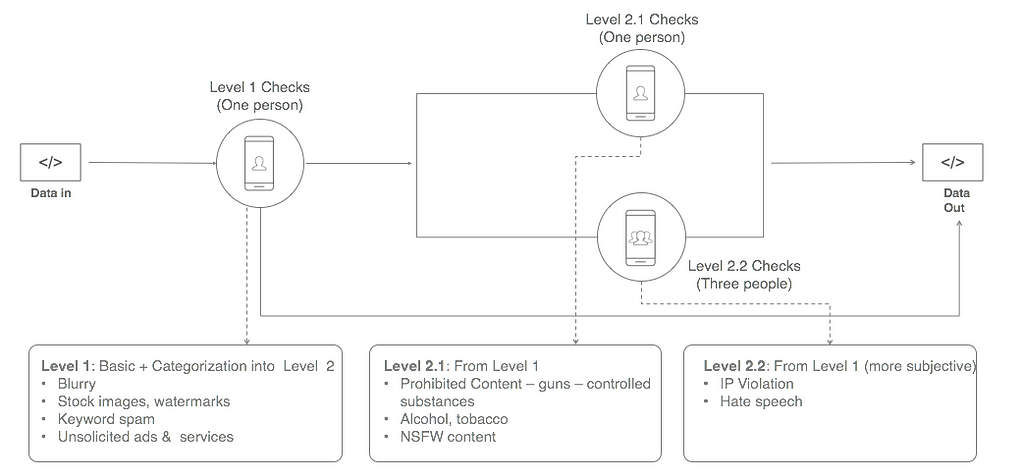
Optimized workflow accounting for 80/20 rules
STEP 6
Think Worker Training (nobody likes this but you have to do it)
Not everyone’s got special skills like Liam.

One key rule for workflows and efficient supply chain is that not everyone’s good at everything
The key to more optimized workflows is efficient task allocation and work orchestration. Ideally, we should break down the work down if possible. Training the workforce is a separate and massive challenge in itself. We’ll address this in our subsequent post.
For now, here are some ninja skills for your team.
Specific skills for e-commerce workflows
STEP 7
Think Quality Control (what will make everyone more miserable?)
Quality Assurance (QA) is like the finals. It doesn’t matter what you did during the whole year. If you don’t pass, you’re probably not going to college. Please don’t hate us for this ridiculous analogy.
Most large process teams have an audit function built-in and these are the guys your regular ops team would hate because they’re the ones reaching out to you when something goes wrong. Each team has Key Result Areas (KRA’s) built around this. Again, QA is a very elaborate topic and a small section will not do justice to it. Next post! For now, here are some ideas.
Quality can be broken down into two aspects — Capability and Intent. Capability means your worker is qualified and capable of doing the work, and Intent means your worker is doing the work well and doesn’t have any malicious intent.
- Capability Check — Worker Skill Matching: Matching people with the right skill set with the appropriate task will ideally see a jump in both efficiency and quality.
- Intent Check — Quality Algorithms: Traditionally, your manager or the audit team would check your work but that’s much after the damage has already been done. Thanks to crowdsourcing, experts have built several algorithmic techniques to quickly check for issues that could either relate to malicious intent. Some of these include Maker Checker, Redundancy, and including Gold Standard Data. These are used differently depending on the dataset. Too much information — definitely for the next post.
Popular quality frameworks
Measuring Quality

There are a lot of ways to measure quality but the simplest one is sampling.
Statistical sampling is actually pretty simple, and you don’t have to be a statistician to make it work for you. We take you back to high school statistics.
Here’s how it works: if you have a dataset of 10,000 items:
- You need to sample 370 items to be 95% confident that the output is within +/- 5% of where it needs to be.
- You need to sample 6,239 items to 99% confident that the output is within +/- 1% of where it needs to be.
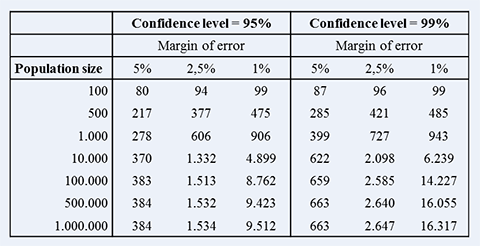
Sample size ready reckoner
Here’s a handy sampling calculator and a brief overview of sampling.
There are two things to take care of here. (a) Deciding on a sampling % based on the severity of risks associated with a particular output. For instance, banks run double data entry for most processes, just to make sure there’s no margin of error. You’re effectively sampling 100% of the data. (b) Ensure the sampled dataset is representative of the entire population.
STEP 8
Think Automation (yay!), finally
There’s a lot of literature (a LOT!) out there on AI, Machine Learning, and Deep Learning. What’s hard is deploying this in production and using it for specific business applications.
Today, there are APIs for MLaaS (Machine Learning as a Service) and Open Source libraries that can be deployed on your cloud. Google, IBM, Amazon, are all building frameworks to deploy generic AI within applications. They’ve created an infrastructure layer, like mobile, so you don’t really need to reinvent the wheel and can use a bunch of pre-existing libraries.
However, the biggest challenge still is the need for more well labeled data while handling more complicated problems. There are a whole number of challenges, which include finding a good data scientist!
Some existential problems include:
- More classes, more data. The more classes (or categories) in a model, the larger is the dataset required to automate that process.

- Hard to use generic models within specific applications. Horizontal AI models (eg NSFW detection) work well for very specific generic use cases but for specific applications such as detecting the ‘neck-line’ attribute for a particular garment, you need a specific model. Also, they need to be trained with data that looks similar to your platform data.
- Dealing with variation in data. Even if you’re able to deploy a model with a lot of effort and it gets you 80%+ accuracy, scaling the last 20% is still painful and requires human input or validation. There will always be exceptions.
For these reasons, companies may deploy a workflow with a human in the loop (HIL)
An HIL framework does 3 things:
- Validate the output provided by the AI model: You need to sample the algorithmic output for a while until such a time that you’re confident to make sure there are fewer and fewer false positives. Donuts and bananas still get tagged as NSFW (Not Safe For Work) sometimes.
NSFW donut
- Handle exceptions: When your algorithm fails to detect a ‘concept’ beyond a certain threshold of confidence (and that will happen), you need a human to come in and deal with that exceptions.
- Re-train your model: The human validated inputs help improve the model with time, adding more training data, increasing it’s accuracy with time.
Some ideas to help you get going — go for low hanging fruits
There are a whole bunch of things that you can automate, and probably should. Instead of automating for all classes and all scenarios, it’s probably a better idea to go after some low hanging fruits, with limited variables and complexities, to get incremental improvements. Not only do these move faster in production, they’re likely to give you incremental cost efficiencies quickly. One way to justify that salary!
For example:
- Example 1 — Say if 10% of your images were rejected because they were blurry, you could just deploy a model to check for blurry images first, before doing anything else. If you do this well, you’ve brought about 10% incremental efficiency very quickly.
- Example 2 — If your dataset follows an 80/20 rule and say you have 10 categories that a particular product falls under, you could train a model to detect the top 2 categories first that account for 80% of the data. This is simpler because of fewer classes of data. You can then simply get humans to look at the remaining 20% of the data. You just got nearly 80% incremental efficiency here. The cost of deploying the model for all 10 categories might not justify the return.
Here are some libraries you can use and here’s what your workflow will look like with automation, with a human-in-the-loop.
Examples of standard AI libraries
Future Posts on AI: Some things that we’re working on
- Efficient AI experiments to decide which models are worth investing more time in.
- Return on Investment (ROI) on automation — a quantitative tool to help you decide if a certain problem is worth the investment from an automation standpoint.
STEP 9
Rinse and Repeat (Until you can successfully retire on that island)
So you’ve deployed some specific AI models within your workflow and here’s what it’s looking like.
Product Quality Control
Optimized workflow for Data Quality Control with human-in-the-loop machine learning
Product Enrichment
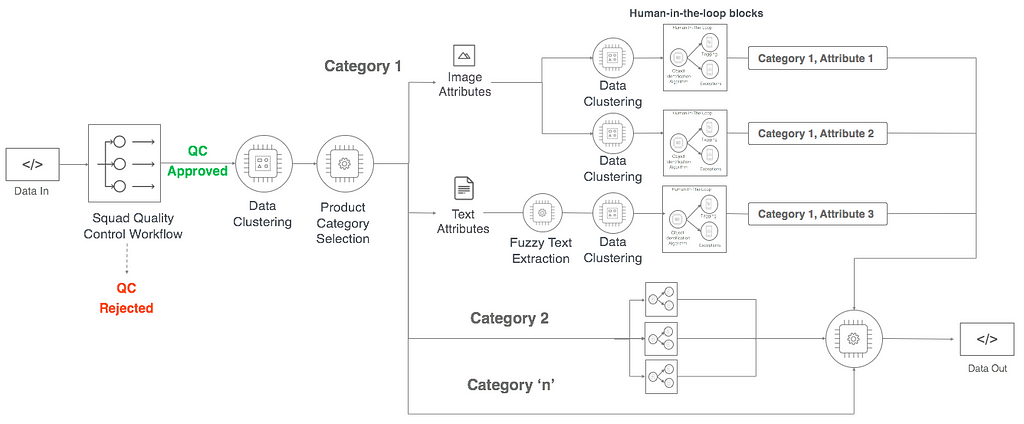
Optimized workflow for Data Enrichment with human-in-the-loop machine learning
Results and Outcomes:
Product Quality Control
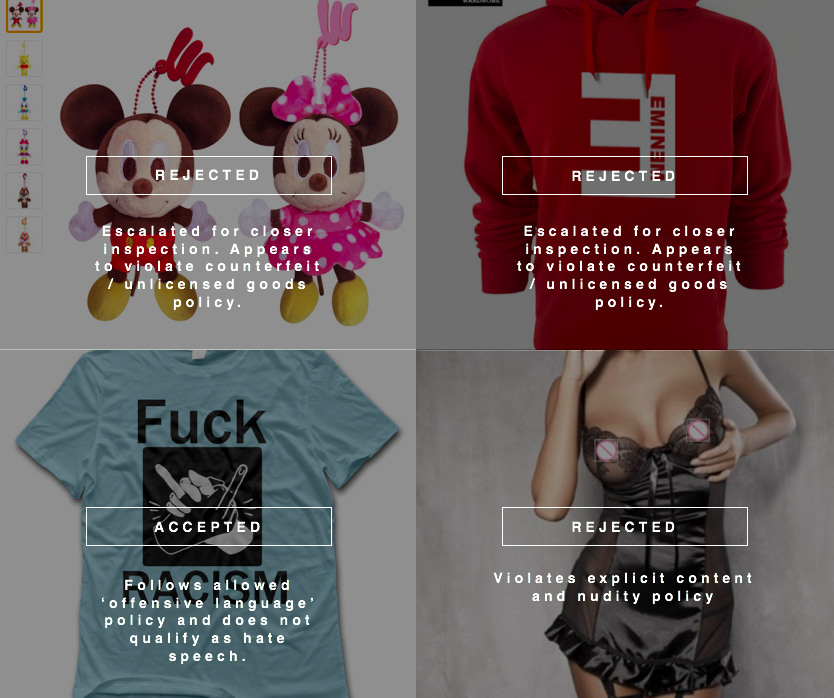
Product Enrichment
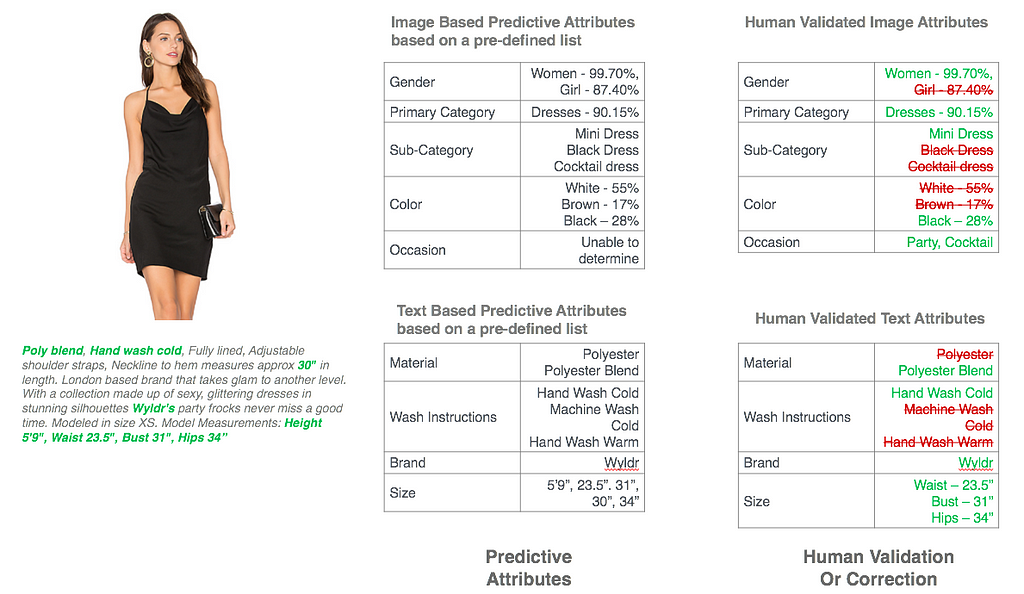
There are a whole lot of ways to solve your business processes and scale your company. This is just one approach that has worked for some of the best technology companies in the world. There’s a lot of work that remains to be done for mid-market businesses trying to grow quickly.
At Squad, we have believe that HI and AI are stronger together. So, we developed a smart workflow builder that gives enterprises access to high-quality automation and a highly curated and quality distributed workforce in a single platform. This helps scale business processes with unprecedented SLAs of speed,accuracy, flexibility, and cost. Our customers today include Uber, Sephora, Teespring, the Flipkart Group, Snapdeal, the Tata Group, etc.
Learn more at www.SquadPlatform.com
